Offices: Gurgaon, Jaipur, Indore, London, Dubai, Sweden

Automating Operations
Offices: Gurgaon, Jaipur, Indore, London, Dubai, Sweden
We enhanced the Yolo model’s accuracy and robustness through image augmentation and computer vision, optimizing OCR and object detection for comprehensive document data extraction, showcasing the synergy of AI techniques in a successful project.
The client is a leading name in paperless accounting solutions, aimed to redefine accounting practices by offering a platform for managing accounting documents. They required the digitalisation of the accounting documents like invoices, eway bills etc for more efficient and reliable service. For the same extraction of relevant and important keyoint information from documents was essential for which different artificial intelligence techniques were implemented in a systematic framework.
During the implementation phase, several challenges arose. Firstly, there was a scarcity of data available for training, particularly for specific voucher types or document categories, which posed a hindrance to effective model development. Secondly, achieving a high level of accuracy for the object detection model proved to be a demanding task. Lastly, the extraction of information from a wide range of documents, regardless of their varying quality, posed a significant challenge when utilizing the OCR method. These obstacles were met with innovative solutions to ensure the successful digitalization of accounting documents and the extraction of essential information.
To enhance the accuracy and robustness of the Yolo model, we employed a set of effective strategies. Firstly, we implemented plausible image augmentation techniques on the document images, enabling the model to perform better. Additionally, we integrated computer vision methods to enhance the overall quality of document images, optimizing optical character recognition (OCR) and ensuring the extraction of comprehensive information. The AI techniques applied in this project encompassed two critical components: object detection and OCR.
For object detection, we employed a state-of-the-art real-time system that was trained on the client’s documents, with prior identification of relevant Regions of Interest (ROIs) within the documents for comprehensive data extraction. The OCR component was carefully curated, and OCR algorithms were meticulously implemented. These techniques, combined with computer vision methods, yielded the best possible results. Furthermore, natural language processing was incorporated to ensure the proper formatting of the output, contributing to the project’s overall success.
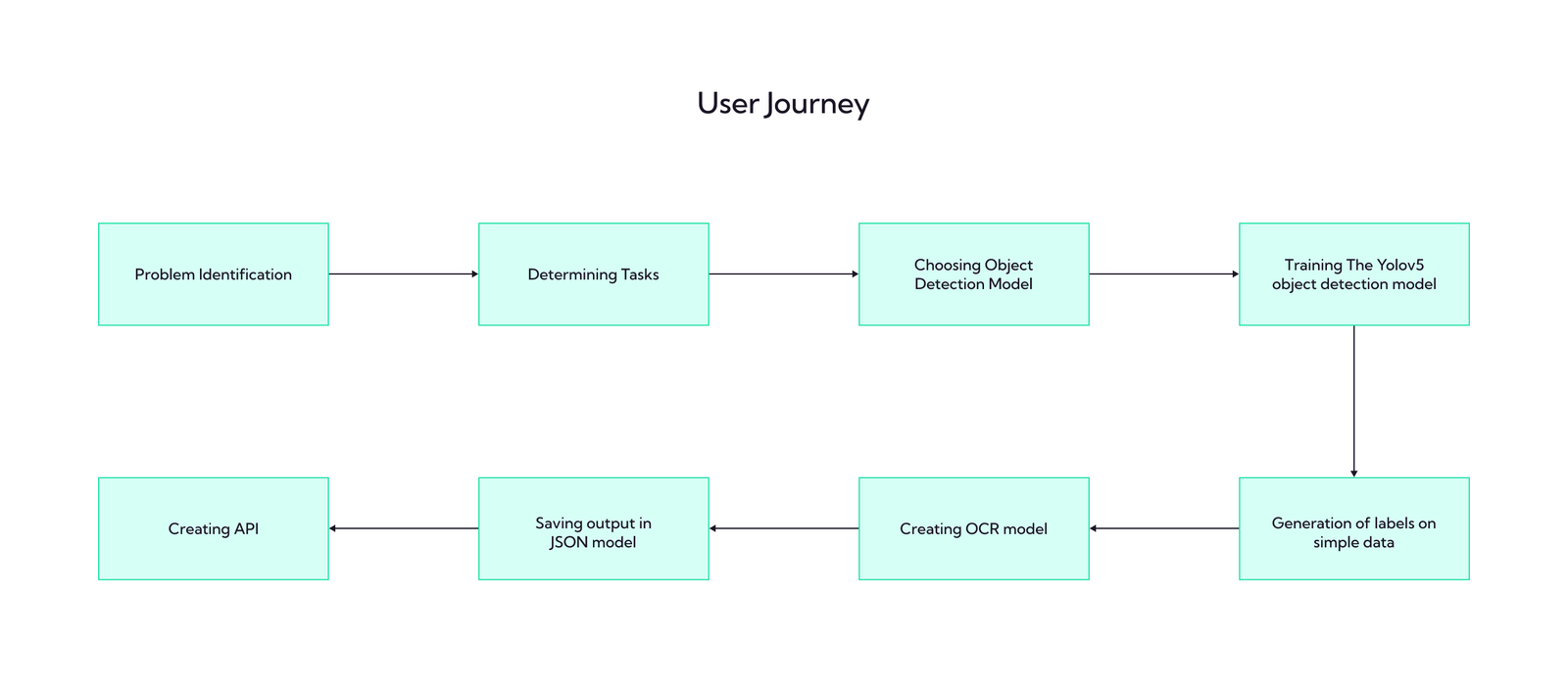
We were able to achieve 95% accuracy for the Yolo model on detecting the correct fields from a given document as well as were able to process almost all possible voucher types for which the data was available from the client side in the most efficient manner.
Planning to outsource software development services?
Contact sales, to start a project, now.